
Graphcore: NVIDIAを脅かす"謎のAI半導体メーカー"
Published: December 15, 2017
予測
スタートアップが活躍できないと考えられていた半導体業界。しかし、ムーアの法則が崩れ、ディープラーニングなどの機械学習の新しい手法が現れたいま、AIに特化した半導体には大きな機会が横たわっている。そしてIoT時代の200億のコネクティッドデバイスもまた埋め込まれるAIチップを心待ちにしている。
1. AI時代のGPUの台頭とネクストGPU
半導体チップはソフトウェアよりもはるかに開発コストが高く、最近まで急進的なイノベーションが既存のプレイヤーを淘汰する余地はほとんどどない業界だった。長い間続いた、効率性をめぐる競争のせいで、新興企業は極めて薄い利益率を強いられ、インテルのような既存業者に押し出される。インテルは25年間連続でマーケットシェア首位をとっている。
しかし、地殻変動が起きている。AIの広範な応用が期待されている中でNVIDIAが画像処理能力を存分に活かし、ビットコインのマイニングにまでその能力を示そうとしている。機械学習の国際学会の前には世界中のGPUリソースが逼迫状態になるほど、GPUはこの領域で欠かせないインフラになった。 下記の図のようにあらゆるフレームワークにおける学習で、NVIDIAのGPUはその時間を飛躍的に加速させている。NVIDIA CEOのJensen Huangは「AIはソフトウェアを飲み込んでいる(AI Is Eating Software)」と表現し、「AIの時代はGPUの時代(The Era of AI Computing – The Era of GPU Computing)」と話していた。
ただし2020年までに200億のインターネットに接続されたデバイスが世の中に出回ることが予想されているが、NVIDIAのGPUを含む現在のプロセッサでは要求 を十分に満たすことは難しい。
NVIDIAを除く唯一の大手GPUメーカーであるAMDは、AI業界に積極的にマーケティングすることに興味を持っていないようだ。インテルとマイクロソフトはAIチップの未来として「FPGA」に賭けている。
Googleは5月にTPU(Tensor Processing Unit)を発表。クラウドでの提供を想定しているようであり、各クラウドTPUは最高180テラフロップのパフォーマンスを提供し、最先端の機械学習モデルを訓練して実行するための計算力を提供するとうたっている。傘下のDeepMindは驚異的な学習速度を達成した「Alpha Go Zero」のレポートでTPU採用の効果に触れている。

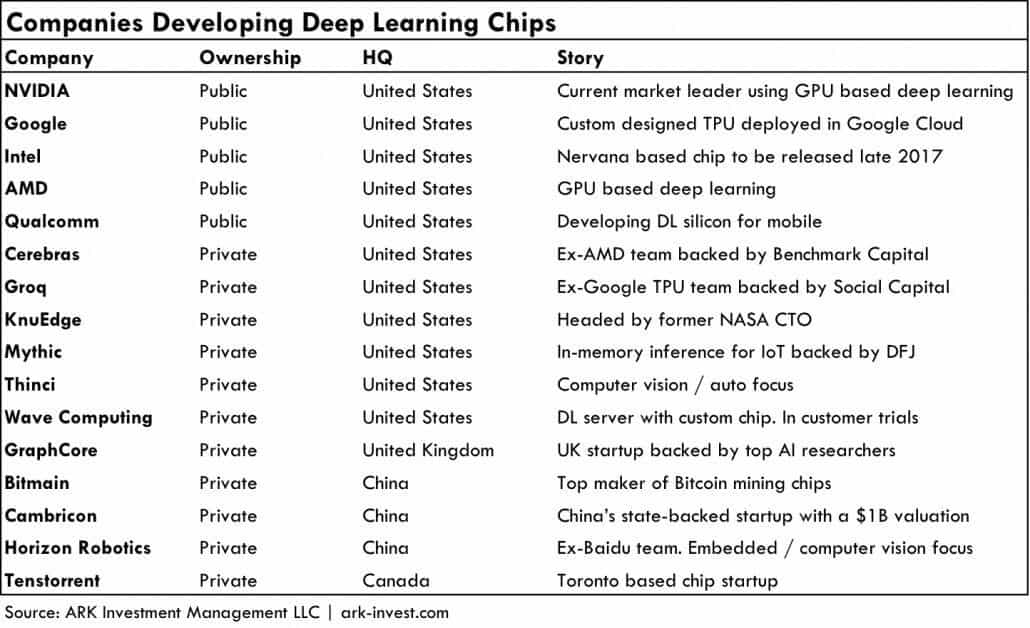
同時にAI特化の半導体スタートアップが雨後の筍のように出現しているのだ。新しいアーキテクチャを採用したチップは、NVIDIAのGPUを上回るパフォーマンスに挑戦し始めている。AIチップの開発企業は以下の通りで、Bitmainというビットコインの最大マイナーかつASICメーカーまで参入している。巨大企業とスタートアップが肩を並べる「戦国時代」の様相だ。
2. 彗星のGraphcore
Graphcoreが11月始めに最近シリコンバレーの有力ベンチャーキャピタルであるSequoia Capitalから5000万ドルを調達したのはとても端的なできごと。Graphcoreがこの調達の前に資金調達した際の株主はDeepMind CEOのDemis Hassabis、UberのチーフサイエンティストZoubin Ghahramani、OpenAIの研究者らを含んでおり、AI開発の最前線にとっていかに重要な企業かが理解できる。
「一般的な人工知能を可能にするシステムの構築とは、生データから学び、この学習を広範囲のタスクに渡って一般化できるアルゴリズムを開発することを意味する。これには多くの処理能力が必要であり、Graphcoreのプロセッサーを支える革新的なアーキテクチャーには大きな期待が寄せられている」とDemis Hassabisは語っている。
Graphcoreのコア製品は「Intelligence Processor Unit(IPU)」。消費電力を最小限に抑えながら数千から数百万の重みを実行する、機械学習に必要な種類の急速な計算を行うように設計された新しい種類のプロセッサだ。
3. GPUはゲーム、IPUは機械知能
Graphcoreのブログ「PRELIMINARY IPU BENCHMARKS」によると、Graphcoreは「IPUは現在と将来の機械学習作業の双方に前例のないレベルのパフォーマンスをもたらす新しいAIアクセラレータ。大規模な並列コンピューティング。大規模にマルチタスクを並列実行するコンピューティングと、IPU内または複数のIPU間の同期、革新的なデータ交換ファブリック、および大量のオンチップSRAMの独自の組み合わせにより、幅広い機械学習アルゴリズムにわたる訓練と推論の両方における見違えるような能力を提供する」と説明している。
2016年のシリーズAの段階ではIPUに関して以下の3点を記述した。
- 他のAIアクセラレータと比較して、 学習と推論の双方においてパフォーマンスを10倍から100倍向上する
- 訓練と推論の両方で優れている
- 機械学習開発者は、IPUの採用により、最良の代替アーキテクチャでも機能しないモデルやアルゴリズムで革新を起こすことができる
CEOのNigel Toonはセミコンダクター業界に30年在籍し、複数の特許を取得し、スタートアップ2社を売却したヒッターである。そのうち1社は彼がいま追い抜こうとするNVIDIAに売却した。
Toonは以下のように主張している。
- 「デナード・スケーリング」という法則に沿って高密度化と高速化が進んできたが、その法則に陰りがみられる
- ニューラルネットワークの学習には多量のメモリが必要であり、ここがボトルネックになるとしている
- GPUはゲーミングに最適化されたものであり、次世代の機械学習にとって最適ではない
- 人間の脳のアナロジーから、プロセッサーのコアがインターコネクトすることが重要だ
GraphcoreのJamie Hanlonのブログによると、メモリを従来のプロセッサに組み込むことは、はるかに低い電力消費で巨大な帯域幅を開くことによってメモリボトルネックの問題を回避する1つの方法になる。しかし、オンチップメモリは高価であり、DNNを訓練しデプロイするため現在使用されているCPUとGPUプロセッサのなかに、外部にあるメモリを追加することはできない。
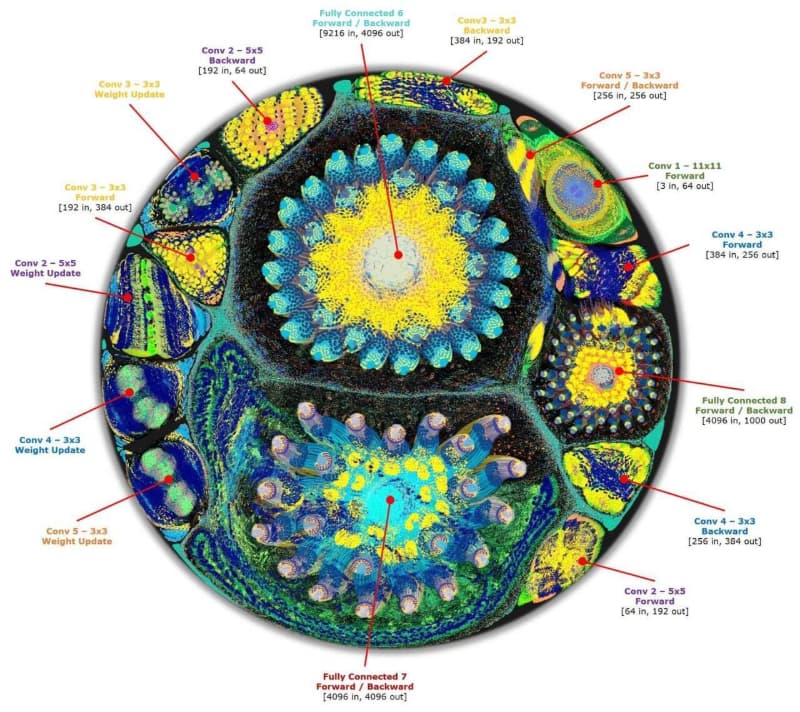
Toonらは人間の脳と同じ働きをするようなコンピューティングに未来を感じており、畳み込みニューラルネットワーク(CNN)の働きを以下のようにビジュアライズしている。
4.GPUを上回るAIアクセラレーション IPUシステムは多層の畳み込みニューラルネットワーク(CNN)でのトレーニングで現存する、あらゆるチップでの学習を上回る成果を出せるとGraphcoreは主張している。「IPUシステムを使用することは既存のテクノロジーを大幅に上回るパフォーマンスをもたらす」というのだ。RESNET−50の学習における、300W GPUアクセラレータ(C2アクセラレータと同じ電力バジェット)で報告される最高のパフォーマンスは約580画像/秒だが、IPUのパフォーマンスは大きくそれを上回る。
すべてのリカレントネットワーク(Recurrent Neural Network)には、現在のチップアーキテクチャの課題であるデータ依存性が含まれている。データの依存関係により、使用可能な並列処理の量が制限される。 IPUおよびPoplarライブラリは、大量のオンチップメモリの可用性と、IPU内での計算およびデータ移動の柔軟性によって、これらの制限をよりよく処理する。
推論を実行するサーバでは、レイテンシ制約、すなわち、結果を得るまでの推論の要求からの最小の所要時間がある。以下の表は、GPUと比較して、さまざまなレイテンシ制約に対する単一レイヤロングショートタームメモリーネットワーク (Long Short-Term Memory Network)の推論のパフォーマンスを示している。Graphcoreの主張では差は歴然たるものだ。
Graphcoreは近くIPUの提供を開始する予定である。また、Graphcoreの投資家の並びは、ビジネスサイドにもその商機を納得させるものといっていい。
5. Cambricon
Graphcore同様注目をあつめるのが、中国のCambricon Technologies(寒武纪科技)。Cambriconは10億デバイスで自分たちのAIプロセッサを搭載し、3年間で中国のハイパフォーマンスAIチップ市場の3割をつかむという強気の目標を掲げている。
中国の科学技術省が人口知能を含む革新的なプロジェクトに対して、長期的に積極的な投資を行うことを宣言しているが、Cambriconはその流れの中で中国政府系ファンドやアリババから1000万元の出資を受け、すでに企業価値が10億ドルを超えるといわれる。
Cambriconもニューラルネットワークの学習においてNVIDIAのチップをまさる効率を提供できると喧伝する。
HuaweiのKirin 970チップは、最新の旗艦スマートフォン「Mate 10」のために開発されたもので、Cambriconの知的財産を使用している。 Cambriconの技術は国有企業Sugon Information Industryによって開発されたサーバーでも使用され、より高速なコンピューティングとより良い推論機能を提供していると主張されている。
6. 雨後のタケノコ
他にもAIチップスタートアップは多数存在し、中にはステルスのまま補足されていないものもあるかもしれない。
2010年創業のカルフォルニアのWave Computingは合計8000万ドルの資金を調達している。同社は特許取得済みの「データフローアーキテクチャ」は「CPUやGPUの必要性を排除し、従来のディープ・ラーニング・ソリューションで見られる典型的なパフォーマンスとスケーラビリティのボトルネックを排除する」と説明。GPUに対して1000倍のニューラルネットの学習速度を提供できると主張している。
KnuEdgeは昨年ステルスから突然業界に現れたが、彼らは秘密主義の塊のような企業である。彼らのウェブサイトには従業員のプロフィール以外の情報がありません。VentureBeatの記事によれば、KnuEdgeは既に収益を上げており、いままで調達した1億ドルに加え、今年より多くの資金を調達することを検討していたことがわかっている。
Horizon Roboticsは年初のCES 2017でIntelと提携しAdvanced Driver Assistance System (ADAS) を発表。Mideaと提携し、インテリジェントエアコンディショナーを発表した。ホームセキュリティの問題を解決するという用途は極めて新しい。同社はBrain Processing Unit(BPU)と呼ばれるAIチップを開発している。
トロントのTenstorrentは2016年に設立され、「深い学習とスマートハードウェア向けに設計された次世代の高性能プロセッサASIC」を創出するために、未公開のシード調達をした。彼らのチームはNVIDIAやAMDの卒業生で構成されている。この隠密なスタートアップについてはあまり知られていない。
カリフォルニアのThinCIは、2010年に設立され、すべての機器にビジョン処理をもたらす技術を開発するための資金を調達している。スマートデバイスが、クラウドとの定期的な通信を必要としないでコンピュータビジョンなどの機能を持つ能力は「エッジコンピューティング」または「フォグコンピューティング」と呼ばれている。それがThinCIがプレーしたい場所である。
結論
以前は投資家に投資案件をもっていくと腹を抱えて笑われたという半導体スタートアップだが、AIチップの可能性が認識された最近は、急激に風向きが変わってきている。GPUがAIの学習能力を飛躍的に高めたように、AIチップは新しいコンピューティングの可能性を切り開きそうだ。